やりたいこと
UTF-8の文字を扱うようなプログラム(エディタみたいな)を作成した場合に、どこまでテストするのか?
を考えてみたので、備忘のため記録しておきます。
背景
ここは読み飛ばしても大丈夫です。
趣味で作っているプログラムなので、普段はあまり力をいれてテストしないのですが、
たまたま動かしてたら、片仮名の「ム」が文字化けする現象が見つかりました。

調査したところ末尾のバイトがa0の文字は文字化けすることがわかりました。
内部で使用しているプログラムのバグと思われるので、この現象自体は、一般的なことではないのですが、
文字コードのバイトのパターンで文字化けしたりするんだなぁという気づきがありました。
そこで、もうちょっとテストしてみよっかなと。
結果
いきなり結果ですが、こんな感じでテストしてみようと思ってます。

もともとのバグは1バイト目がa0の場合に発生するものだったので、とりあえず各バイト単位でパターンを網羅することで、類似のバグを見つけることができると思いました。
各バイトの取りうる値はwikipediaの記事を参考にしました。
https://ja.wikipedia.org/wiki/UTF-8
5バイト, 6バイトはUnicodeでは不正なシーケンスとあるので、考えないことにしました。
また、制御文字も除く予定です。
具体的に
テストする文字はバイトさえ網羅できれば任意ですが、
実際に使用する文字をこちらのページを参考に選定していきます。
https://seiai.ed.jp/sys/text/java/utf8table.html
1バイト目の2X~7Xまではこんな感じです。 ASCIIを網羅するような感じとなります。黄色い部分です

1バイト目の8X~BXは、2バイト/3バイト/4バイトのどの文字にも使われるのですが、一番若い物を使うことにすると以下のようになります。黄色い部分です
また 2バイト目のCX、DXを適当に抽出していきます。(緑色の部分)
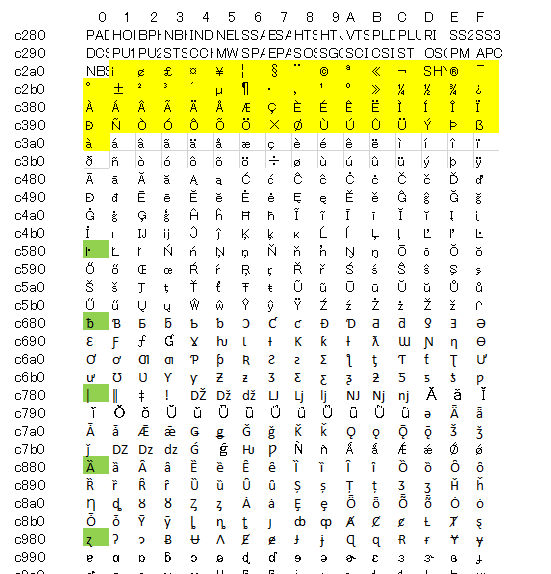
こんな感じで繰り返していこうと思ってますが、文字を選ぶのがめんどくさそう...
追伸
UTF-8の4バイト文字の一覧表がweb上で見つからなかったことと、
途中で面倒になったことから、4バイト目と3バイト目は網羅することを断念しました。
テストできたところは下図の緑色のところです。

統合漢字拡張B~Dの文字の文字コードは調べてみたのですが、
F0AXXXXXしかみあたらず、3バイト目が8X,9X,BXとなる文字がどれなのか、分かりませんでした。
調べるのには、Google IMEの文字パレットを使用しました。

UTF-8の文字コードが表示されるので、便利です。
多分3バイト目が8X,9X,BXとなる文字は、U+E0000以降のどれかなのかとは思っているのですが、Googleの文字パレットだとCJK互換漢字補助までしか表示されないので(上図)、ここまででやめることに。








